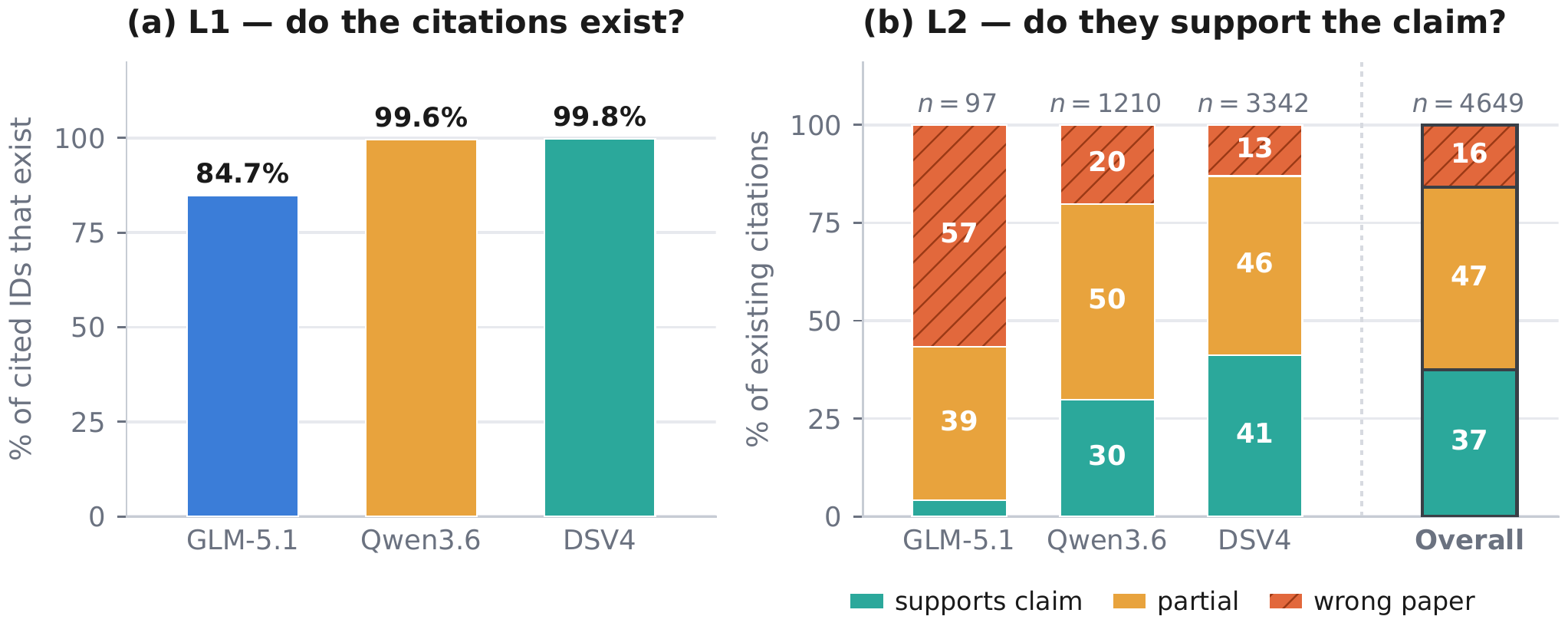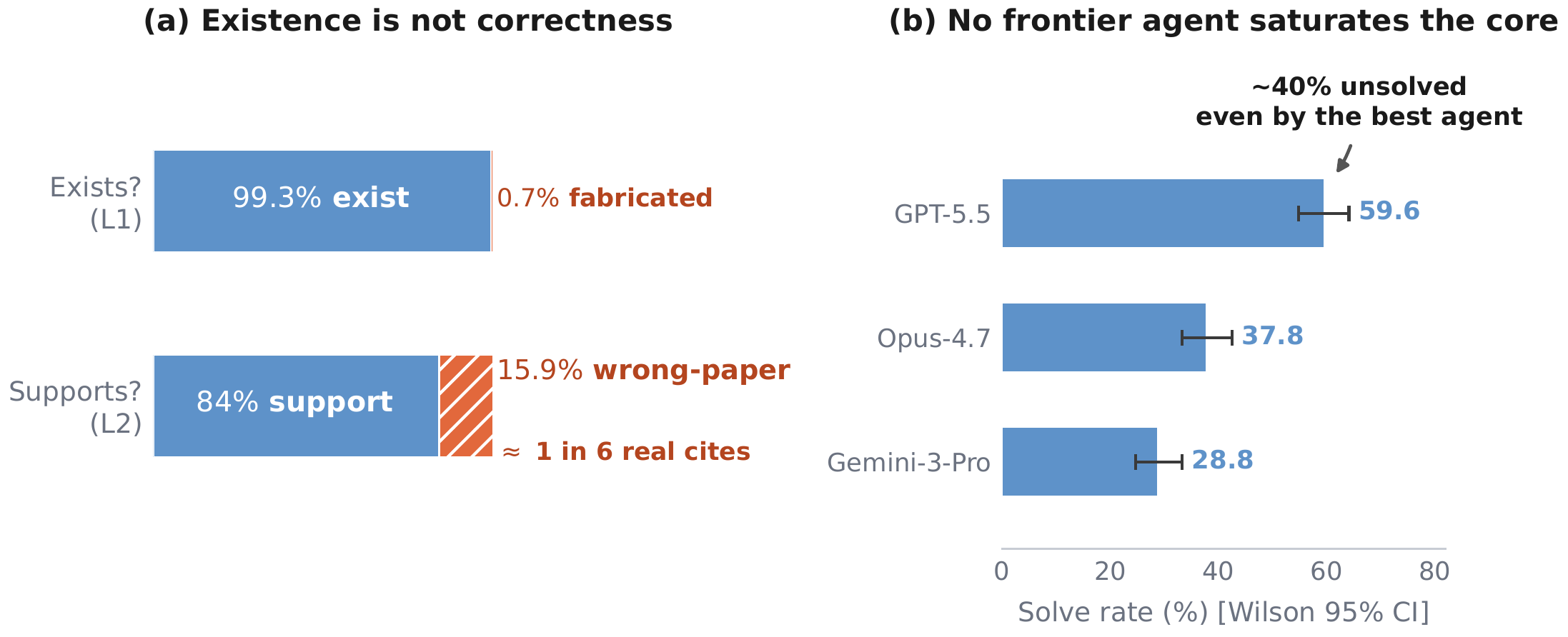
A working citation looks like proof — but the fact that a link resolves does not mean the cited paper supports the claim. Current agentic models rarely fabricate citations (over 99% resolve), yet roughly 15.9% link to the wrong paper. Existing benchmarks miss this failure mode: when a question has a fixed answer key, a model can reproduce the expected source from that key rather than independently verifying that the source supports the claim.
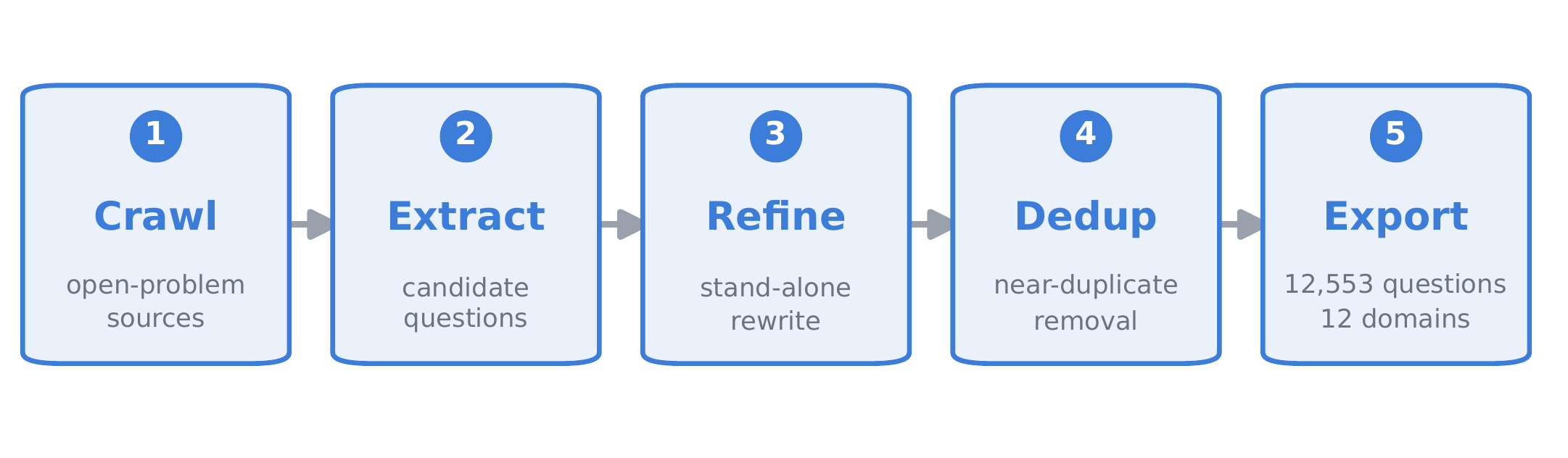
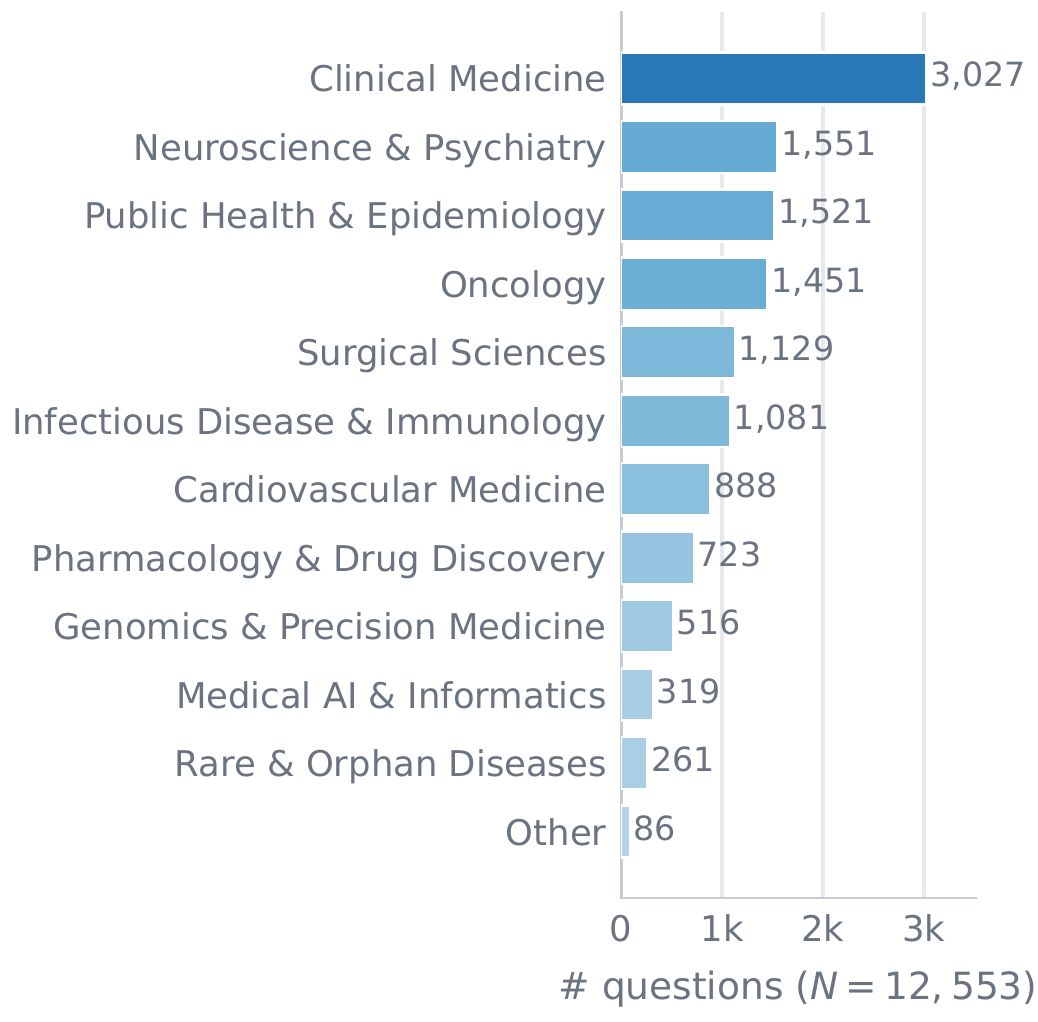
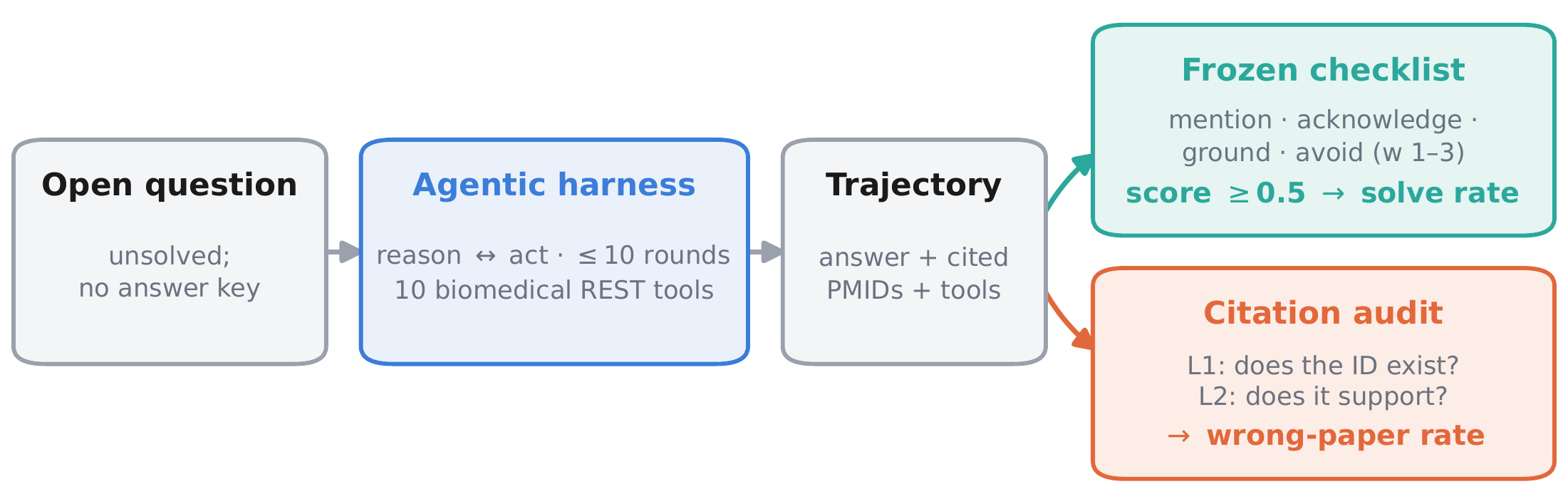
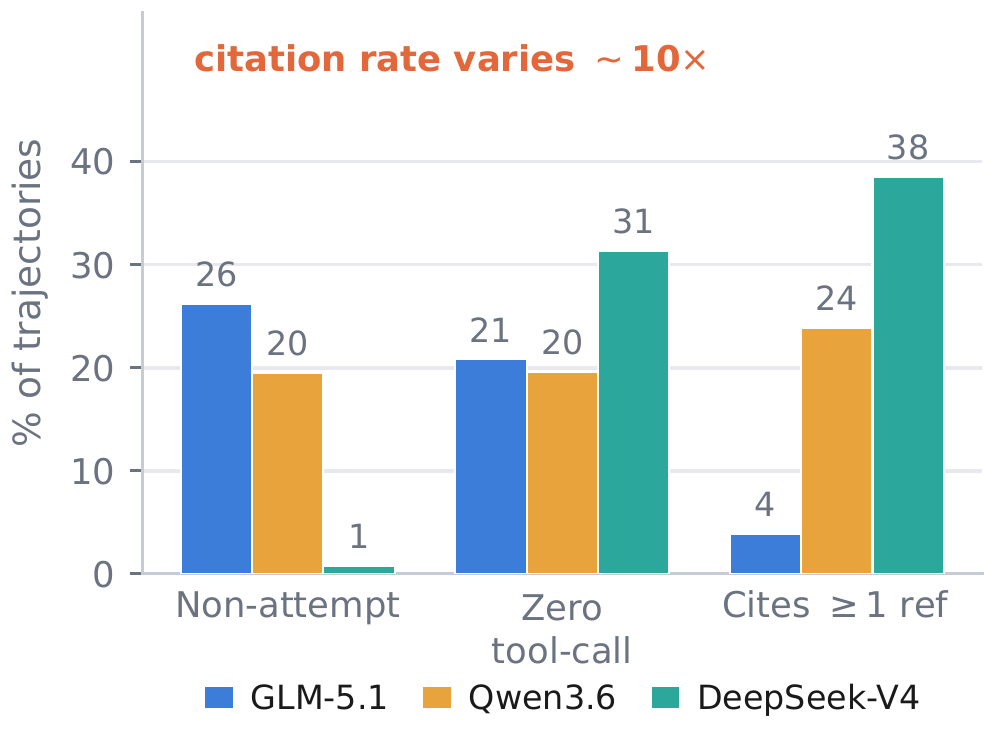
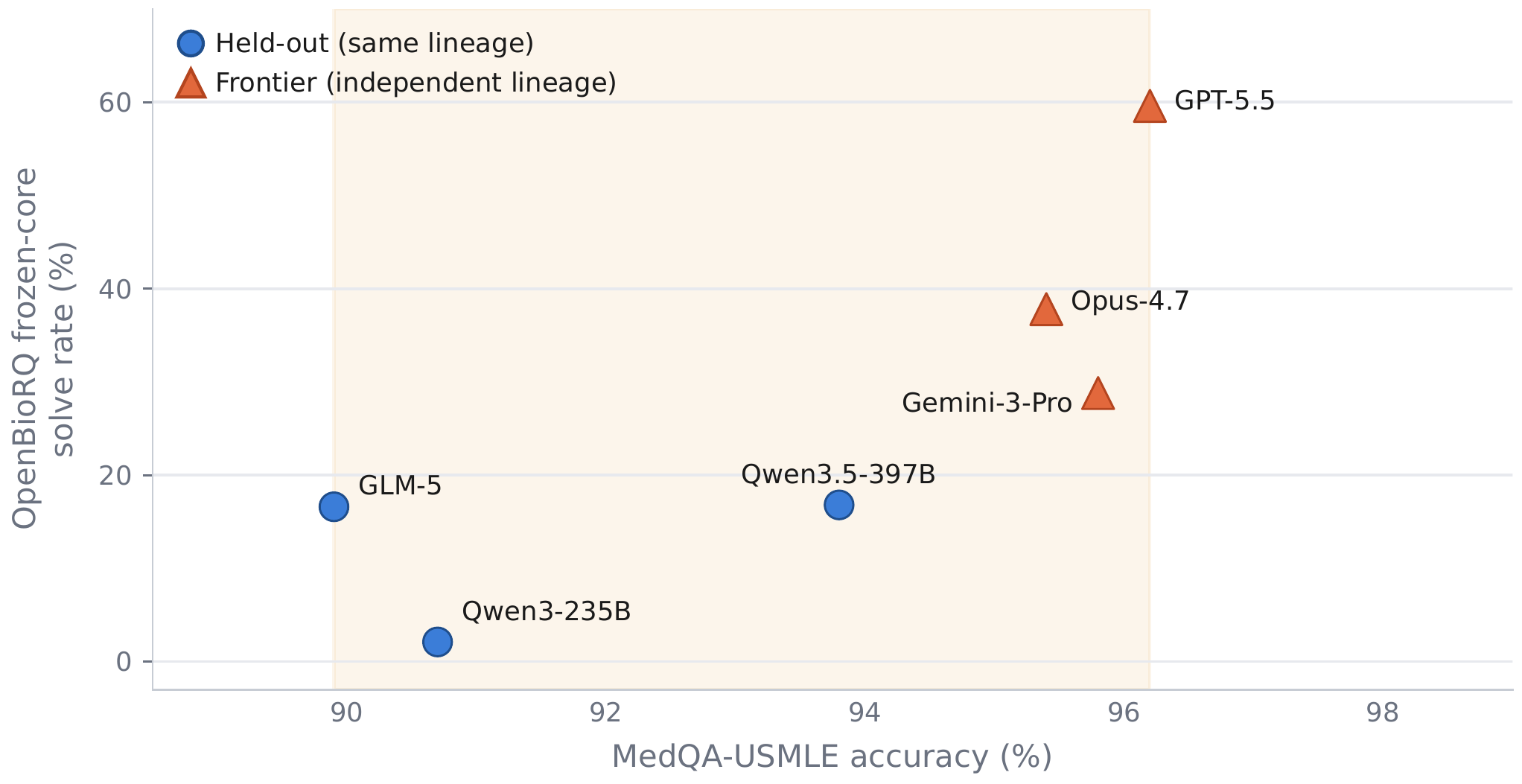
I introduce OpenBioRQ, a retrieval-grounded agentic benchmark of 12,553 unsolved biomedical research questions across 12 domains that treats open questions as a faithfulness-and-abstention probe. To my knowledge, this is the first biomedical benchmark to combine an agentic setting — where the model must issue multiple tool calls — with unsolved questions that have no answer key. Openness is verified against real follow-up evidence rather than a model's parametric knowledge, and difficulty is empirical: anchored on questions that three open-weight reference models fail to answer. Beyond difficulty, I observe agentic collapse on the hardest questions, where agents stop using their tools — and for the most collapse-prone model, blocking tools entirely barely changes its score. A frozen per-question checklist raises inter-judge agreement from Spearman 0.35 to 0.82. OpenBioRQ targets research assistance — evidence retrieval and faithful citation — not clinical decision support.